
Отбор лексического материала
Методы математической статистики используются для случайной выборки из “генеральной совокупности” как модели источника данных. Случайная выборка статистически отображает генеральную совокупность, но при этом должны быть устранены все субъективные, неслучайные факторы образования выборки. В наших исследованиях без полной уверенности о случайном характере выборки сознательно планировалось взять большее количество элементов, чтобы предотвратить искажение конечных результатов. Однако особенность графоаналитического метода такова, что случайность и объем выборки определяются ее достаточностью для отражения внутренней структуры генеральной совокупности, чего нельзя добиться при малом объеме случайных данных. Поэтому данные собирались в объеме “доверительного уровня”, который обеспечивал построение графической схемы отношений родственных языков. Сам факт построения схемы свидетельствует о существовании внутренней структуры данных. Если же на основании собранных данных построить схему отношений близкородственных языков не удается, то это является свидетельством либо некорректности данных, либо об отсутствии родства между отдельными языками, принятыми к исследованию.
Распространенное мнение о большой нестабильности лексики может быть объяснено тем обстоятельством, что во многих языках имеется довольно много заимствованных слов. Однако наблюдения показывают, что заимствования относятся преимущественно к более “культурному” слою слов, а древнейшие слова, которые соответствуют состоянию этноса более низкого культурного уровня, все-таки в языке остаются. Эти древнейшие слова в языке вместе с тем и самые употребительные. По мнению А. В. Десницкой исконная лексика включает в себя значительную часть наиболее употребительных слов, которые отображают элементарные понятия и создают наибольшее количество словообразующих гнезд. (Десницкая А. В., 1966, 9). О зависимости частоты употребления слова от его возраста говорят в своей работе Арапов и Херц:
Существует связь между частотой слова и временем возникновение его в языке…Большинство слов с большой частотой употребления – это древние слова, и наоборот – чем меньше частота слова, тем больше шансов, что это слово является новообразованием (Арапов М.В., Херц М.М., 1974, 3)
Авторы отмечают, что впервые эту связь заметил Дж.Ципф в 1947 г. и оценил его значение для количественного анализа фактов, которые касаются истории языка. Следует, однако, иметь в виду, что некоторые слова с малой частотой могут быть древними, и есть много новообразованных слов, которые имеют большую частоту употребления, но эти новообразования очень легко изъять при лексико-статистических исследованиях по их смыслу.
Известно, что бывают такие языки, в словаре которых большинство слов иноязычного происхождения, но в общем обращении все-таки находится больше собственных слов, и потому даже такие языки и по своей лексике не производят впечатления принадлежности к другой языковой группе. В таком состоянии находится румынский язык, в котором по происхождению больше всего слов славянских, за ними следуют латинские, турецкие, новогреческие (Mańczak Witold,1981, 99), но и живой румынский язык, и тексты, писаные на этом языке, все равно производят впечатление романского, а не славянского. Игнорирование или непонимание факта зависимости давности слова от его частоты употребления в языке запутывает языковедов в вопросе первичного родства языков, осложняет различение извечной и заимствованной лексики, что в конце концов заводит ученых в тупик. Примером может быть формальный и догматический подход В. Пизани к вопросу о происхождении английского и румынского языков, когда этот ученый считал возможным говорить о родстве английского и французского, с одной стороны и румынской и славянских, с другой (Пизани В., 1966, 11). Такой подход осложнял итальянскому лингвисту воссоздание истории развития языков, особенно если принять во внимание, что он не исключал возможности родства индоевропейских языков с языками других языковых групп при том, что исключал возможность существования прародительского языка (Там же, 21).
Проблема разделения слов общего происхождения и поздних заимствований в родственных языках является одной из самых сложных в историческом языкознании. Ее хорошо понимают все компаративисты, потому что она сразу возникает при сравнительном анализе любых языков разной степени родства (Фортунатов Ф.Ф., 1956, 72; Menges Karl H., 1990, 117 и др.). Выбирая для исследований даже наиболее употребительные слова для лексико-статистического анализа с учетом их значений, мы всегда подвергаемся определенному риску включить в списки какую-то часть древних слов иноязычного происхождения. Однако для большинства языков их бывает относительно немного, и если провести специальный анализ отобранного лексического материала с целью исключения заимствованных слов, то этот риск существенно уменьшается, и возможные ошибки уже существенно не влияют на результаты исследований. Исключение более поздних заимствований облегчается тем, что иногда известно, из каких языков в исследуемом языке имеется больше всего заимствований. Например, в тюркских языках имеется много заимствований из арабского и иранских, в иранских – из арабского и тюркских, в славянских – из германских, тюркских, балтийских, в германских – из латинского, в албанском – из славянских и турецкого и т. д. Правда, речь идет о более поздних заимствованиях, того времени, корда носители языков уже разошлись со своих прародительских ареалов. До того времени заимствования из одной группы языков в другую тяжело отделить от слов собственного происхождения. Но при определении ареалов первичных поселений, как мы увидим далее, это не имеет большого значения.
В принципе, сам отбор данных мог бы требовать минимума профессиональных знаний и был бы чисто технической работой при наличии, доступности и полноте этимологических словарей. К сожалению, все эти три условия не выполняются. Для некоторых языков этимологические словари все еще не составлены, для других они только составляются и полностью не вышли из печати. Не все этимологические словари, вышедшие в свет, были в наличии в публичных библиотеках бывшего Советского Союза. Например, автору не удалось поработать с этимологическими словарями древнеиндийского, албанского, финского, венгерского, английского, чувашского и некоторых других языков, которые уже в свое время были опубликованы. Систематизации материала в определенной мере мешала и неполнота данных в этимологических словарях. В них очень редко дается полный набор соответствий из других родственных языков, чаще авторы ограничиваются примерами из наиболее известных, а иногда некоторые ошибочные этимологии кочуют из словаря в словарь.
Все эти обстоятельства вынуждали большую часть работы по поиску и отбору данных вести внимательным пересмотром двуязычных словарей, в которых в большинстве случаев можно найти очень богатый материал. Однако и здесь не хватило некоторых словарей. В соответствии с темой работы необходимо было бы обработать словари самодийских языков, но из-за их отсутствия эта робота не была проведена вообще. Однако наиболее негативное влияние на результаты исследований оказало отсутствие или неполнота словарей некоторых иранских языков. В результате, к примеру, остается загадкой происхождение белуджского, мазендеранского, бахтиарского, татского и некоторых других языков, хотя они, очевидно, начали формироваться на территории Восточной Европы. Точно также из-за отсутствия полных данных остается гипотетическим происхождение некоторых славянских языков: македонского, кашубского и языков полабских и поморских славян.
Работа со словарями языков разных языковых семей не требует особенного знания всех этих языков, необходимое знание их фонетических особенностей и закономерностей их исторических изменений в соответствии с требованиями и известными принципами сравнительно-исторического языкознания (Фортунатов Ф.Ф., 1956; Мейе А., 1938; Мейе А., 1954; Гамкрелидзе Т.В., Иванов В.В., 1982; Мельничук О.С., 1966 и др.). Для оценки звуковых соответствий при подборе и та систематизации слов индоевропейских языков использовалась работа Г.Краге (Krahe Hans, 1966). При роботе и финно-угорскими языками использовались данные из работы В.И..Лыткина и Е.С.Гуляева (А. Лыткин В.И., Гуляев Е.С., 1970), а для тюркских языков звуковое соответствия оценивались по Н.А.Баскакову (Баскаков Н.А., 1960). Не следует забывать также и об опыте, который приобретается в процессе многолетней работы. Кроме практического усвоения методов языкознания этот опыт доказывает также, что их применение безусловно необходимое в пределах одного языкового рода для языка более низкого и языков высшего уровня в процессе дивергентного развития. Однако при взаимовлияниях языков разных языковых семей фонетические закономерности иногда нарушаются, поэтому в определенных случаях к рассмотрению привлекались слова одного и того же значения разных языковых семей, которые не совсем укладывались в рамки фонетических соответствий, когда было очевидно, что их соответствие не могло быть случайным. Особенно это было обосновано тогда, когда такие слова находились в языках разных семей, но в языках носителей из соседних ареалов поселения.
Исследования проводились на лексическом уровне без учета грамматических форм со сравнением лексических единиц в двух планах – звуковом и смысловом. Совпадение звуковых форм без уверенности в совпадении содержания безоговорочно отбрасывалось. При оценке смысловой стороны изоглосс соответствие отождествлялось от максимального значения – синонимия через большее или меньшее подобие семантики к антонимии, которая иногда бывает просто следствием специфичности понятия (классический пример – первоначальное значение "край" может в разных языках получить значение "начало" и "конец"). Синонимия здесь понимается как совпадение хотя бы одного значения слова в разных языках (чаще всего доминирующего), но не полное совпадение смысловых полей. Правда, чаще всего в исследуемом материале преобладали не синонимы, а слова подобного значения общего происхождения, даже не обязательно той же грамматической категории.
Количественная оценка фонетической и смысловой степени подобия изоглосс не делалась, хотя есть слова более или менее похожие по значению и фонетически подобные в большей или в меньшей степени. Отбор проводился по правилу: факт либо есть, либо его нет.
При обработке больших массивов лексики одного уровня, количественная оценка отдельных фактов становится несущественной, потому что ее возможный диапазон не может идти ни в какое сравнение с самим количеством фактов, и в таких условиях она все равно бы достаточно равномерно распределилась среди этих фактов по закону больших чисел. В подавляющем большинстве случаев подбор изоглосс в языках не составлял больших трудностей, и закономерности взаимоотношений между группой родственных языков устанавливались уже на первичном материале. Когда эти взаимоотношения становились достаточно очевидными, в ряде случаев было хорошо видно, в каких языках недостает соответствий для той или другой изоглоссы. Это бывало тогда, когда изоглосса принадлежала отдаленным ареалам и отсутствовала в тех, которые лежали между ними. В таких случаях, как для пополнения материала, так и для проверки правильности установленных связей велся целенаправленный поиск соответствий в языках промежуточных ареалов. Это была наиболее интересная форма работы, потому что очень часто соответствия находились, но развитие семантики у них иногда бывало неожиданным, хотя и достаточно обоснованным. Например, в финно-угорских языках были найдены фонетически подобные слова со значением "сирота" – фин. orpo, ест. orb, вепс. armatoi, венг. arva, хант. urvi, которые, возможно, считаются заимствованными из индоевропейских языков, потому что ни В.М.Иллич-Свитыч в списке ностратических, ни Н.Д.Андреев в списке бореальных слов финно-угорские аналоги не приводят.
При обработке больших массивов лексики одного уровня, количественная оценка отдельных фактов становится несущественной, потому что ее возможный диапазон не может идти ни в какое сравнение с самим количеством фактов, и в таких условиях она все равно бы достаточно равномерно распределилась среди этих фактов по закону больших чисел. В подавляющем большинстве случаев подбор изоглосс в языках не составлял больших трудностей, и закономерности взаимоотношений между группой родственных языков устанавливались уже на первичном материале. Когда эти взаимоотношения становились достаточно очевидными, в ряде случаев было хорошо видно, в каких языках недостает соответствий для той или другой изоглоссы. Это бывало тогда, когда изоглосса принадлежала отдаленным ареалам и отсутствовала в тех, которые лежали между ними. В таких случаях, как для пополнения материала, так и для проверки правильности установленных связей велся целенаправленный поиск соответствий в языках промежуточных ареалов. Это была наиболее интересная форма работы, потому что очень часто соответствия находились, но развитие семантики у них иногда бывало неожиданным, хотя и достаточно обоснованным. Например, в финно-угорских языках были найдены фонетически подобные слова со значением "сирота" – фин. orpo, ест. orb, вепс. armatoi, венг. arva, хант. urvi, которые, возможно, считаются заимствованными из индоевропейских языков, потому что ни В.М.Иллич-Свитыч в списке ностратических, ни Н.Д.Андреев в списке бореальных слов финно-угорские аналоги не приводят.
Когда в результате исследований стало известно, что, действительно, как и считалось ранее, финский, эстонский и вепсский языки принадлежат к западной части общей финно-угорской области, а венгерский и хантыйский – к восточной, то возник вопрос о причине отсутствия этого слова в языках коми, удмуртском, марийском, мордовском, ареалы которых находятся между западнофинскими и угорскими языками. Поэтому был проведенный целенаправленный поиск соответствия в указанных языках. В коми и удмуртском ничего похожего не было найдено, а вот в мордовском языке эрзя было найденное слово урьва "сноха". Семантическая связь станет понятной, если вспомнить, что у древних народов был обычай, или даже закон брать женщин из другого рода. В таких условиях и сама женщина, и все ее новое окружение имели все основания считать ее сиротой. Здесь все ясно. В марийском же языке был найден возможный дериват арваты "молодуха". Семантически это слово близко к мордовскому, и его можно было бы поставить в этот же ряд изоглосс, если бы не неясный формант -ты, который в финно-угорских языках не встречается и может быть тюркского происхождения, тюрка, хотя бы его можно было бы сравнить с похожим вепсским -toi, но в тюркских языках, есть подобное слово со значением "женщина" : тур. avrat, гаг. аврад, азер. арвад, есть оно и в иранских языках: тадж. аврат, язг. – awrat, шугн. – awrat, сарык. ewrat. В словаре Э.В. Севортяна (А.Севортян. Э. В. 1974) слово отсутствует, следовательно оно иранского, арабского или еще какого-либо другого происхождения. В арабско-русском словаре (А. Баранов Х.К., 1989) ничего подобного не было найдено и сомнения относительно этимологии слова остались. В конце концов углубление в эту проблему было признано лишним и слова с корнем arvat/avrat с широким значением "женщина" были изъяты из всех таблиц. Но тот факт, что мордовское урьва соединило две области финно-угорских языков, дает основания считать, что оно могло быть распространено также и в марийском, удмуртском и коми. В таких условиях его заимствования из индоевропейских языков становится сомнительным. Тогда мы должны внести его в ностратический фонд и допустить возможность существования парного брака уже на сильное ранней стадии развития человека.
Мы долго остановились на этом примере для того, чтобы, во-первых, проиллюстрировать методику работы в условиях отсутствия этимологических словарей, потому что общее описание не даст хорошего о ней представления, а во-вторых, в данном случае видно, что в соответствии со спецификой исследований особенное углубление в частичную проблему является излишним, потому что усилия не стоят результата в условиях, когда имеется множество бесспорных фактов. Однако решение подобных проблем является чрезвычайно важным для изучения истории культуры наших далеких предков. Но оно должно было бы осуществляться в исследованиях другого направления. В процессе же проведенных исследований было обнаружено достаточно много подобных случаев, но их даже попутное рассмотрение займет слишком много места. Впрочем, в процессе последующего изложения некоторые примеры еще будут приводиться.
Хронологически первыми были проведены исследования славянских языков на основании выборки, составленной на материалах двуязычных словарей опять же с учетом звуковых соответствий (Мейе А., 1951; Bräuer Herbert, 1961; Бернштейн С.Б., 1961). Сразу же после получении подтверждения действенности графоаналитического метода исследования были повторены на материалах этимологических словарей О.Н.Трубачева и Ф.Славского (A. Sławski F., 1974; А. Трубачев О.Н., 1974), дополненных данными словарей Фасмера, Безлая, Мельничука, Шустера-Шевца и др. (А. Фасмер М., 1964; А. Bezlaj France, 1976; А. Мельничук О.С., 1982). На основании всех этих исследований был составленный список общеславянских слов, который практически совпал с данными словаря основного словарного фонда Ф.Копечного (A. Kopečný František, 1981), за исключением того. что в список вносились преимущественно только одно слово славянского корня, а у Ф.Копечного приводитсят много однокорневых слов. На основе этого списка после согласования его с частотными словарями русского языка (А. Засорина Л.Н., 1972; Штейнфельдт Э.А., 1973) был составлен список сем, который в дальнейшем использовался как основа при исследовании языков финно-угорской, тюркской и иранской групп. Индоевропейские языки исследовались только на основе данных этимологических словарей, причем три четверти данных было взято из словаря Ю. Покорны (A. Pokorny J., 1949-1959), которые после были дополнены материалами из других словарей (А. Boisaq E., 1923; А. Fraenkel E., 1955-1965; А. Walde A., 1965; А. Frisk H., 1970; А. Hübschmann Heinrich, 1972; А. Kluge Friedrich, 1989).
Как уже было указано, при исследовании финно-угорских, тюркских, иранских и германских языков использовался список сем, составленный на основе списка общих славянских слов В процессе исследования каждой из групп родственных языков использовались два типа таблиц словарей. Сначала для группы языков составлялась своя таблица-словарь первого типа, в крайнюю левую колонку которой вписывался список сем, а в последующих колонках для каждой позиции списка выписывались из словарей все имеющиеся синонимы для каждого из исследуемых языков. После этого проводился анализ полученных наборов синонимов на фонетическое соответствие, что давало возможность отбирать изоглоссы, которые потом дополнялись дополнительными словами при анализе других наборов синонимов с подобным содержанием. Например, всегда сравнивались наборы синонимов со значениями : "высокий", "гора", "верх" или "плести", "вязать", "ткать" и т.д. В процессе работы со словарями достаточно часто появлялись новые изоглоссы, открытые случайно, они тоже включались в список. В конце концов составлялась таблица-словарь второго типа, в которой в крайней левой колонке давался полный набор идентификаторов изоглосс (для лексических изоглосс – предполагаемые праформы корней), а в последующих колонках – имеющиеся соответствия в отдельных языках. Тогда уже каждая изоглосса заново проверялась по всем словарям и при этом приходилось включать в таблицу достаточно много новых слов. Дополнений и уточнений бывало настолько много, что таблицы приходилось переписывать по пять-семь раз.
Графоаналитический метод
Применяемый метод, названый автором графоаналитическим, базируется на использовании одного из видов графов, который, возможно, еще ждет своего описания в математике (автор, по крайней, мере в теории графов его не обнаружил) и может пока что характеризоваться как “взвешенный” граф, в котором связи существуют не между отдельными узлами, а обязательно между ними всеми, причем важной является не только сама связь, но и расстояние между каждым из узлов. Суть метода состоит в поиске точных координат узлов графа на основании неточных данных о длине ребер, которые их соединяют. (В случае, когда длина ребер известна точно, определение этих координат не составляет большого труда, в геометрии это элементарная задача). В нашем случае мы отыскиваем координаты центров мест поселений носителей отдельных языков, имея неточные данные о количестве общих слов в парах родственных языков, поэтому и длина ребер графа является приблизительной. В принципе построение графа возможно, если длина ребер не очень искажена, но узлы уже будут выглядеть не отдельными точками, а множеством компактных точек. Чем компактнее будут расположены точки в пределах множества и чем далее одно от другого расположены эти множества, тем точнее построен граф. Далее мы будем строить подобные графы в наших исследованиях, но существует вероятность того, что эти построенные нами графы будут получаться случайно. Попробуем вычислить эту вероятность.
При существовании графа A, состоящего из некоторого числа n узлов, соединенных между собой ребрами, а каждый узел имеет (n – 1) ребер. Как известно из математики, для размещения точки на плоскости нам нужны только две координаты в любой системе координат. Для нашего графа, при комбинации отрезков ребер между собой по два, мы можем получить гораздо большее число пар координат. Точное их число С, может быть вычислено по известной формуле:
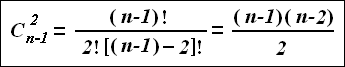
При числе узлов n = 6 мы будем иметь количество пар координат С = 10, при n = 10 число возрастает до С = 36, при числе узлов n = 12 мы получим С = 55. 6 место Следовательно, при n большем или равным шести место каждого из узлов графа относительно других (n – 1) узлов мы можем получить десятками разных способов. В нашем случае для графа А при использовании всех возможных способов размещения узлов на плоскости с помощью ребер известной длины узлы всегда попадут в одну точку. При исследовании реальной системы, каковою, например, является система взаимоотношений родственных языков, нас удовлетворит граф В, каждый из узлов которого будет состоять из множества точек, занимающих определенную площадь, не перекрываемую площадями других узлов. Если у нас, например, число исследуемых объектов n = 6 и они занимают площадь, величина которой S = 1, то каждый из объектов займет максимум участок размером s = 1 / 6. В таком случае вероятность того, что при построении графа В хотя бы одна точка попадет на свой участок тоже равна 1 / 6. Для шести объектов каждый из его узлов мы можем построить десятью разными способами, тогда вероятность того, что все десять раз одна и та же вершина попадет в ту же площадь будет равняться 1/610 = 1 : 604 660 176. Поскольку у нас шесть объектов, то эту величину нужно умножить саму на себя еще шесть раз. Тогда в знаменателе будет величина с восьмьюдесятью нулями. Уже эта величина не поддается воображению. Когда же у нас число объектов будет увеличено до десяти, то количество нулей в знаменателе будет равняться 3600.
Чтобы не усложнять восприятие, приведенное здесь доказательство было проведено несколько упрощенно, но сами себе порядки полученных величин говорят в пользу того, что в случае построения графа по имеющимся данным о его случайности не может быть и речи. Указанное упрощение объясняется тем, что построение точек по их координатам несколько отличается от обычной. Действительно, в геометрии для построения любой точки нужно иметь только две координаты, но координаты могут иметь положительные и отрицательные значения. Мы используем только положительные числа, поэтому двумя координатами можно построить две точки, взаимные положения которых будут зеркальными. Метод построения имеет определенные особенности, когда логика подсказывает, точку из возможных нужно брать. Общий ход построения таков, что точки надо располагать от центра схемы, приблизительное расположение которого становится известным уже при построении первых трех центральных точек, то есть для тех языков, которые имеют между собой больше общих слов (признаков) – сначала откладывается отрезок, соответствующий наибольшему количеству слов в парах языков, а далее на базе этих двух точек по координатам строится третья. Собственно, только здесь мы стоим перед выбором – в какую сторону надо откладывать координаты третьей точки, и это делается произвольно, поэтому конечная схема может иметь два варианта, которые зеркально отражают друг друга. Но сомнений при выборе одного из двух вариантов не бывает никогда, потому что почти всегда известно, какие языки являются западными, а какие восточными или северными и южными. Когда же построено по одной точке каждого узла, то тогда исчезают всякие сомнения вообще – из двух возможных вариантов берется тот, при котором точки одного узла лягут наиболее тесно. Так делается для всех пар координат, но весь процесс требует проведения нескольких итераций, потому что выбор начала координат (центра узла) является несколько произвольным. Поскольку каждое ребро в качестве координаты используется несколько раз в комбинации с другими, то чертеж становится перегруженным большим количеством линий и точек, среди которых можно запутаться. Поэтому, когда данные довольно точны, можно каждое ребро использовать в качестве координаты только один раз. Тогда каждый узел будет состоять только из (n – 1) точек, каждая из которых является концом одного из ребер. Общее число ребер равно величине, которую можно вычислить по формуле:
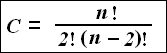
Более детально процесс построения схем родства по лексико-статистическим данными будет рассмотрен на конкретном примере ностратических языков в следующей главе.
Графоаналитический метод может найти применение не только в языкознании, но и в других науках, где проявляется корреляция между большим количеством общих признаков разных объектов и расстоянием между объектами в пространстве (необязательно даже в двухмерном). Этот метод был проверен, например, на статистических данных Федорова-Давыдова (Федоров-Давыдов Г. А., 1987) о количестве общих признаков орнаментальных композиций среднеазиатской керамики, произведенной несколькими мастерами, жившими в разных частях Пенджикента. Поскольку художественные взаимовлияния мастеров были тем сильнее, чем ближе они между собой проживали, то стало возможным определить расположение их мастерских на территории города. Конечно, проверить эти данные невозможно, поскольку неизвестно, где в действительности жили мастера, но сама возможность построения уже является определенным свидетельством действенности метода.
Нужно особенно подчеркнуть, что графоаналитический метод эффективен только при обработке абсолютных величин или отнесенных к одной общей. Отнесение количества общих признаков между двумя объектами к их общему количеству в этих языках или в одном из них не может достаточно характеризовать эти два объекты, поскольку общее количество признаков какого-либо из объектов само зависит от расположения объекта среди других. Маргинальные объекты имеют меньшее общее количество признаков, характерных для этой ассоциации, и это уже характеризует их периферийное положение. Когда же мы возьмем это сниженное значение в знаменателе, оно нам искусственно увеличит соотношение. Это не означает, что маргинальные объекты вообще имеют меньшее признаков. Они их могут мать даже и больше, но их часть может уже быть общей не с объектами исследуемой ассоциации, а соседней.
